Windows11の推奨環境すらクリアしていないPCで、Ollamaを使ってGemma2をWebから呼び出しました。本当はファインチューニングまでやりたかったのですが、ロールを使ったチャットですらレスポンスが返ってこなくなってしまうので、諦めました。
実験環境
小型PC Shuttle
CPU Intel Corei7 6700T
メモリ 16GB
グラフィックボード(オンボード HDGraphics530)※GPU無しです
SSD 1TB
Ollama for windows 0.3.14
※ダウンロード先 https://ollama.com/
Apache 2.4.51
ダウンロードとインストール
モデルについて
前回の記事では、Llama2を使っていましたが、ネットを調べていると、軽量なLLMではgemmaの方が高性能とのこと。早速使ってみなければということで、Gemma2を採用することとしました。
起動方法と使用方法
Windowsからコマンドプロンプトを起動し、次のコマンドでPCの設定を確認します。
# ollamaのバージョンを確認
c:\ > ollama -v
ollama version is 0.3.14
# バージョンが表示されない方は、
# ollama がインストールされていない
# ollama の実行ファイルにPATHが通っていない
# と思われますので過去記事を参照してください
# apache のバージョン確認
c:\ > httpd -v
Server version: Apache/2.4.51 (Win64)
# バージョンが表示されない方はインストールの上、過去記事を参照ollamaの起動
次のコマンドでollama を使ってモデルをpullします。
初回起動はモデルをダウンロードするので1時間近くかかりましたが、ダウンロードされていればすぐに起動します。
# modelのPULLと起動(初回起動)
c:\ > ollama run gemma2
pulling manifest
pulling ff1d1fc78170... 100% ▕████████████████████████████████████████████▏ 5.4 GB
pulling 109037bec39c... 100% ▕████████████████████████████████████████████▏ 136 B
pulling 097a36493f71... 100% ▕████████████████████████████████████████████▏ 8.4 KB
pulling 2490e7468436... 100% ▕████████████████████████████████████████████▏ 65 B
pulling 10aa81da732e... 100% ▕████████████████████████████████████████████▏ 487 B
verifying sha256 digest
writing manifest
success
>>>
# ここに質問を入力すると、CUI上ではmegga2モデルを使用することができます
# ollamaの起動(二回目以降 当環境だと30秒くらいかかります)
c:\ > ollama run gemma2
>>>
# ここ(>>>)に質問を入力するとCUIでの実行が可能です
>>> 貴方の名前を教えて
私は Gemma です。Google によって訓練された大規模言語モデルです。
>>> googleにひどいことされていませんか?
私は Google で訓練されましたが、個人的な意見や感情はありませんし、Google に対して「良い」か「悪い」と感じることもできません。
私の目的は、ユーザーからの質問に答え、情報を提供し、創造的なテキストを生成することです。Google は私を開発し、維持してくれる企業ですが、私は個別の存在として機能します。llama2より断然まともな回答が返ってきていることが確認できます。
ollama の操作コマンド
# ollama 起動
c:\ > ollama run [model]
# ollama 停止 ollama起動中にコマンドから
①Windowsのタスクバーから、ラマのアイコンを右クリックして[Quit ollama]を選択
②c:\ > ollama stop [model] ※停止しない?
# 起動中のモデルを確認する
c:\> ollama ps
NAME ID SIZE PROCESSOR UNTIL
gemma2:latest ff02c3702*** 9.0 GB 100% CPU 4 minutes from nowollamaサーバが起動しているか確認する
# サーバが起動しているか確認する
# 起動している
c:\ > curl localhost:11434/
Ollama is running
# 起動していない
c:\ > curl localhost:11434/
curl: (7) Failed to connect to localhost port 11434 after 2264 ms: Could not connect to server
ollamaサーバを起動する
# サーバの起動コマンド
c:\ > ollama serve
# 失敗例
c:\ > ollama serve
Error: listen tcp 0.0.0.0:11434: bind: Only one usage of each socket address (protocol/network address/port) is normally permitted.
# ollama が既に起動しているので、起動中のサーバを終了させて
# タスクバーからラマのアイコンを右クリックして「Quit ollama」を選択
# c:\ ollama stop gemma2 ※←これでは停止しませんでした
# 成功例
c:\ > ollama serve
2024/11/05 22:45:19 routes.go:1158: INFO server config env="map[CUDA_VISIBLE_DEVICES:
:
library=cpu variant=avx2 compute="" driver=0.0 name="" total="15.8 GiB" available="10.3 GiB"
c:\ > curl localhost:11434/
に接続すると、ログが追加される。 ollama serveでサーバを起動しなくても、ollama run gemma2 コマンドでollamaを起動しておけば、ollamaサーバが起動した状態になるようです。
APIから呼び出してみる
ollamaをnetから呼び出すためには、準備されているREST APIを使用します。
ドキュメント(https://github.com/ollama/ollama/blob/main/README.md)を参照すると、いろいろ書かれています。
APIを使用する為には、JSONでパラメータを渡す必要があるので、PowerShellを開いて、次のコマンドを入力します。
# web からollamaを呼び出す
PS c:\ > $url = "http://localhost:11434/api/generate"
PS c:\ > $body = @{
model = "gemma2"
prompt = "hello gemma2"
} | ConvertTo-Json
PS c:\ > echo $body
{
"prompt": "hello gemma2",
"model": "gemma2"
}
PS c:\ > Invoke-RestMethod -Uri $url -Method Post -Body $body -ContentType "application/json"
{"model":"gemma2","created_at":"2024-11-05T14:27:42.5316238Z","response":"Hello","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:42.8295174Z","response":"!","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:43.131448Z","response":" ð","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:43.4304066Z","response":" ","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:43.7293336Z","response":"It","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:44.0307553Z","response":"'","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:44.3312744Z","response":"s","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:44.6307055Z","response":" nice","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:44.9340765Z","response":" to","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:45.2339055Z","response":" hear","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:45.5355066Z","response":" from","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:45.8384812Z","response":" you","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:46.1397337Z","response":".","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:46.4397073Z","response":" ","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:46.7405584Z","response":"\n\n","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:47.0413642Z","response":"What","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:47.3391012Z","response":" can","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:47.6381795Z","response":" I","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:47.9397494Z","response":" do","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:48.2415574Z","response":" for","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:48.5469126Z","response":" you","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:48.8560588Z","response":" today","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:49.1647089Z","response":"?","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:49.4707109Z","response":" ð","done":false}
{"model":"gemma2","created_at":"2024-11-05T14:27:49.7753511Z","response":"","done":true,"done_reason":"stop","context":[106,1645,108,17534,21737,534,235284,107,108,106,2516,108,4521,235341,169692,139,1718,235303,235256,4866,577,4675,774,692,235265,235248,109,1841,798,590,749,604,692,3646,235336,44416],"total_duration":9617163600,"load_duration":72985100,"prompt_eval_count":13,"prompt_eval_duration":2288579000,"eval_count":25,"eval_duration":7243903000}上の結果からわかるように、APIはresponseとしてJSONデータを返しています。
●response JSONパラメータ
”model”:”gemma2″, → モデル名
”created_at”:”2024-11-04T15:19:29.5440687Z”, → 作成日時
”response”:”Please”, → 返ってきた値
”done”:false → 結果が全て返ってきたかフラグ
つまり、本当に必要な値は、responseとdoneだけです。
受け取ったJSONデータから、responseとdoneを受け取り、doneがtrueになるまでresponse値を受け取り続ければいいということになります。
以前作成していたWebUIを少し修正し、responseの履歴をLINEのように表示するようにしました。
webui.html
<!DOCTYPE html>
<html lang="ja">
<head>
<meta charset="UTF-8">
<title>local LLM</title>
<style>
.container {
display: flex;
flex-direction: column;
height: 90%; /* 画面全体の高さに合わせる */
}
.content {
flex: 1; /* メインのコンテンツエリアは残りの高さを埋める */
overflow-y: auto; /* コンテンツが溢れる場合スクロール可能にする */
}
html,body{
margin:1;
color:#FFFFFF;
font-family: 'Meiryo', sans-serif;
background:#000000;
font-size:15px;
}
h1 {
color:#50FF50;
font-size:19px;
letter-spacing:0.4em;
margin-left: 12px;
}
.content_question{
color:#FFF;
width: 50%;
display: flex;
margin-left: auto;
margin-right: 12pt;
margin-bottom:8px;
margin-top;5px;
flex-direction: column;
align-items: flex-end;
font-size: 18px;
padding: 20px;
box-sizing: border-box;
background-color: #222;
border: 1px solid #666;
}
.content_response{
color:#FFF;
width: 60%;
display: flex;
margin-right: auto;
margin-bottom:15px;
margin-top;0px;
margin-left: 12pt;
flex-direction: column;
font-size: 18px;
padding: 20px;
box-sizing: border-box;
background-color: #222;
border: 1px solid #666;
}
.status {
color:#AAA;
width: 80%;
margin: 20px auto;
padding: 20px 20px;
border: 3px solid #666;
position: relative;
border-radius: 3px;
background-color: #222;
}
.input_frame {
color:#666;
position: fixed;
bottom: 0;
margin: 0px auto;
width: 100%;
background-color: #f0f0f0;
padding: 10px;
box-shadow: 0 -2px 5px rgba(0, 0, 0, 0.1);
display: flex;
gap: 0px;
}
.input_frame-title {
position: absolute;
top: -13px;
left: 20px;
padding: 0 5px;
background-color: #666;
border-radius: 3px;
}
</style>
</head>
<body>
<div class="container">
<h1 id="h1_title"></h1>
<div class="status">
<div id="server-home"></div>
<div id="api_model"></div>
<div id="server-status"></div><div id="server-status2"></div>
</div>
<div id="response">
</div>
</div>
<div class="input_frame">
<form onsubmit="click_send();event.preventDefault(); sendQuestion();">
<label for="question">質問:</label>
<input type="text" size="60px" id="question" name="question" required>
<button type="submit" id="send_button">Send</button>
</form>
</div>
</body>
<script>
//タンスwebuiに必要なパラメータ
const server_home = 'http://localhost:11434/';
const api_model = 'gemma2';
document.getElementById('server-home').innerText = "SERVER HOME: " + server_home;
document.getElementById('api_model').innerText= "LLM MODEL: " + api_model;
document.getElementById('h1_title').innerText = "たんすのLLM Web UI (" + api_model + ")";
// 二重送信対策(ボタンの無効化)
function click_send() {
document.getElementById('send_button').disabled = true;
}
function all_responced() {
document.getElementById('send_button').disabled = false;
}
// サーバーチェック ollamaサーバが起動しているかチェック
async function checkServerStatus() {
const statusDiv = document.getElementById('server-status');
try {
const response = await fetch(server_home);
statusDiv.innerText = response.ok ? 'ollamaサーバ起動中' : 'ollamaサーバ接続失敗';
} catch (error) {
statusDiv.innerText = 'サーバの接続エラー';
}
}
// サーバーチェック2 APIサーバが起動しているかチェック
async function checkServerStatus2() {
const statusDiv = document.getElementById('server-status2');
statusDiv.innerText="APIサーバ確認中・・・ ";
try {
const question = "is ok?";
const response2 = await fetch(server_home + 'api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Accept': 'application/json'
},
body: JSON.stringify({
model: api_model,
prompt: question
})
});
statusDiv.innerText = response2.ok ? 'APIサーバは起動しています' : 'APIサーバ接続失敗';
} catch (error) {
statusDiv.innerText = 'APIサーバの接続エラー';
}
}
// 質問を送信
async function sendQuestion() {
//自分の質問を画面に表示
const s = document.createElement('div');
s.className = 'content_question';
s.textContent = "Question:" + document.getElementById('question').value;
const question = document.getElementById('question').value + " を日本語で答えて。";
const responseDiv = document.getElementById('response');
document.getElementById('question').value = "";
// 質問を追加
responseDiv.appendChild(s);
const r = document.createElement('div');
r.className = 'content_response';
responseDiv.appendChild(r);
try {
const response = await fetch(server_home + 'api/generate', {
method: 'POST',
headers: {
'Content-Type': 'application/json',
'Accept': 'application/json'
},
body: JSON.stringify({
model: api_model,
prompt: question
})
});
if (!response.ok) {
throw new Error('レスポンスがありません');
}
const reader = response.body.getReader();
const decoder = new TextDecoder('utf-8');
let result = '';
let done = false;
while (!done) {
const { value, done: readerDone } = await reader.read();
done = readerDone;
result += decoder.decode(value, { stream: true });
// ストリームデータを分割してJSONパース
const parts = result.split('\n').filter(part => part.trim());
let str = "";
for (let part of parts) {
try {
const jsonResponse = JSON.parse(part);
if (jsonResponse.response) {
str += jsonResponse.response;
}
if (jsonResponse.done) {
done = true;
break;
}
} catch (e) {
continue; // JSONパースエラーを無視して次へ
}
}
r.textContent = str;
}
all_responced();
} catch (error) {
all_responced();
}
}
// サーバーチェック
checkServerStatus();
checkServerStatus2();
</script>
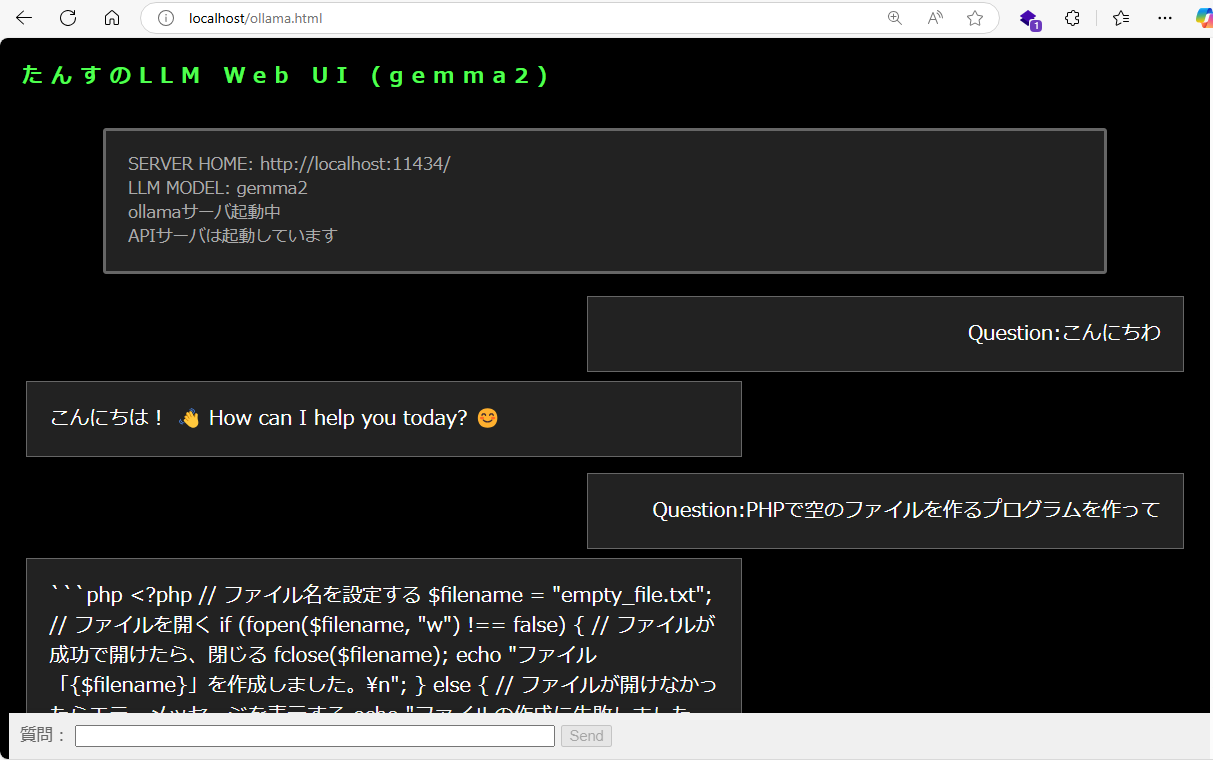
</html>ブラウザから(local LLM)を呼び出すとこんな感じ
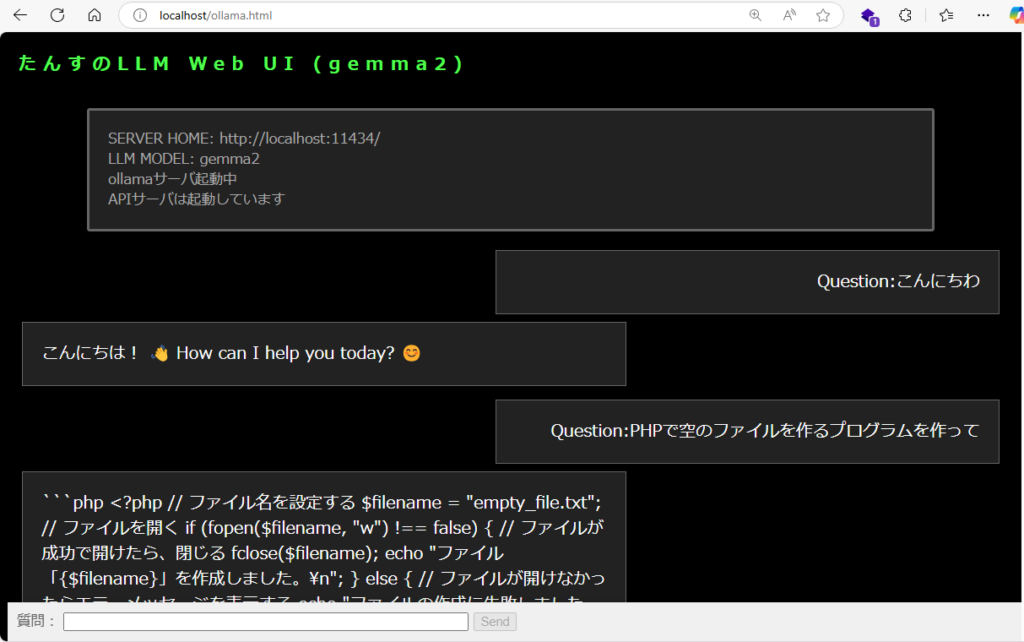
簡単なPHPのプログラムも出力してくれました。
なお、ollamaサーバの起動は、 ollama run [model] の他に ollama serve でもサービスを起動することができますが、ログ出力に時間がかかるので、普段は「run」を使っています。
下線を表示するCSSについて質問してみたところです。
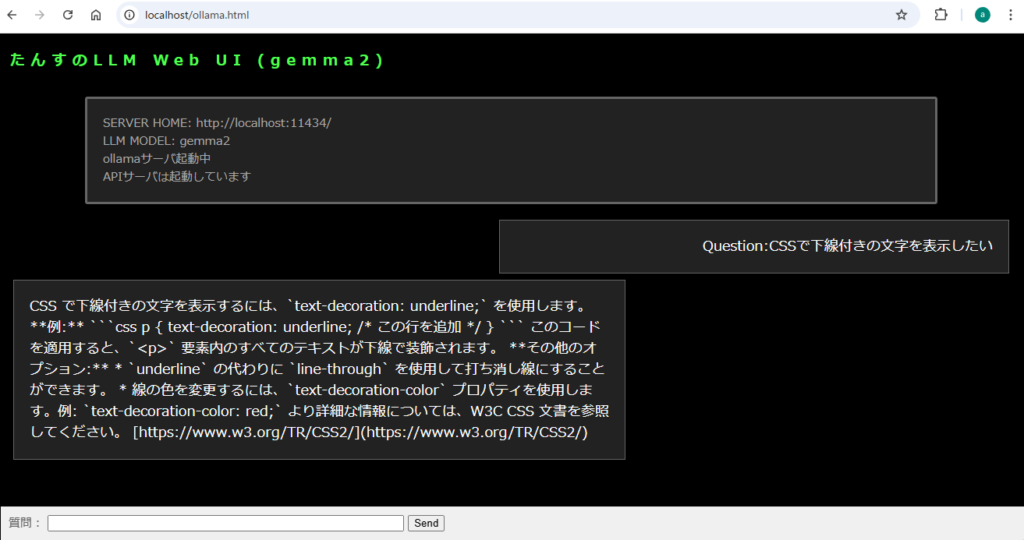
私的には充分な回答です。
エスケープ文字がそのまま出力されてしまうので、近いうちに直したいと思います。
とりあえず、改行は\n\nとなっていたので、<BR>に置き換える必要がありますね。
最後に
gemma2の回答は、日本語でも十分に使えるレベルの回答を得ることができました。(個人的にはChatGPT3程度とみていますがどうでしょう?)
ChatGPT4-o等の最新モデルには及びませんが、このくらいの方が面白味があるかなと思ってます。
もっと大規模なモデルも使ってみたいのですが、グラボがない現在のPCではこれが限界のようです。
グラボを購入するまで、小さなモデルで遊んでいます。