RTX 4060環境(VRAM8GB)でも、pytorchとStable Diffusionを使ってローカル画像生成ができるようなので挑戦しました。
比較的入手が容易なGPUを使っていますので、参考値として下さい。
やりたいこと
ローカル環境でGPUを使った画像生成を行いたい
RTX 4060でどの程度の速度(時間)で画像が出力されるのかを検証
環境
OS Windows11Home
CPU intel Core i7 14700
GPU NVIDIA GeForce RTX 4060(VRAM8GB)
※ドライバ v576.28、CUDA v12.9
Python 3.13 → 3.11 に変更(変更方法は本文で記載)
準備
自身の環境を確認する
ライブラリをインストールするために、自身の環境を確認する必要があります。
①CUDAのバージョン確認方法
②Pythonのバージョン確認方法
①CUDAのバージョン確認
GPUのドライバとCUDAバージョンは次のコマンドで確認しました。
最新のドライバを適用しているので、CUDAは12.9となっていました。
コマンドプロンプト
c:\ > nvidia-smi
Thu Jun 5 08:26:07 2025
+-----------------------------------------------------------------------------------------+
| NVIDIA-SMI 576.28 Driver Version: 576.28 CUDA Version: 12.9 |
|-----------------------------------------+------------------------+----------------------+
| GPU Name Driver-Model | Bus-Id Disp.A | Volatile Uncorr. ECC |
| Fan Temp Perf Pwr:Usage/Cap | Memory-Usage | GPU-Util Compute M. |
| | | MIG M. |
|=========================================+========================+======================|
| 0 NVIDIA GeForce RTX 4060 WDDM | 00000000:01:00.0 On | N/A |
:
※NVIDIA製のGPUが入っていないと動きません
②Pythonのバージョン確認
次のコマンドでPythonのバージョンを確認しました。
# pythonバージョン確認方法
c:\ > python --version
又は
c:\ > py --version
Python 3.13.*
# pythonがインストールされていない
'py'または 'python' は、内部コマンドまたは外部コマンド、
操作可能なプログラムまたはバッチ ファイルとして認識されていません。Pythonのバージョンを3.11にする
3.11にした理由は
ライブラリが充実している(最新のバージョンだと一部のライブラリが対応していない)
3.12ではCVEが発表されている
だからです。
ダウンロードはこちらから → Download Python | Python.org
python3.13等上位のpython versionが稼働している場合は、python3.11をインストールした後、環境変数を変更することでversionを変更することができます。
Pythonのバージョンを3.11にダウングレードする
3.11が稼働している人は読み飛ばしてください。
①python3.11を標準インストール
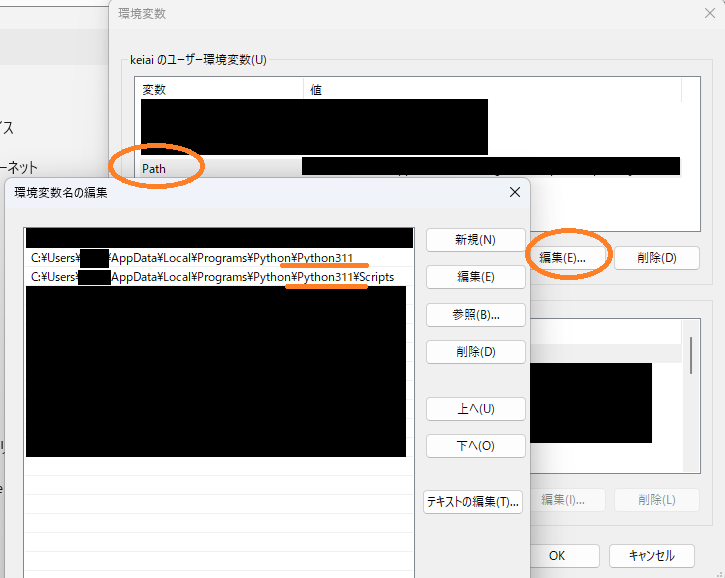
②windowsの環境変数を起動(設定→検索窓に「環境変数」と入力→環境変数ウィンドウを起動)
「Path」を選択して編集、保存後PCを再起動すると有効になります
環境PATHの変更
C:\Users\{ユーザ名}\AppData\Local\Programs\Python\Python313
↓
C:\Users\{ユーザ名}\AppData\Local\Programs\Python\Python313
C:\Users\{ユーザ名}\AppData\Local\Programs\Python\Python313\Scripts
↓
C:\Users\{ユーザ名}\AppData\Local\Programs\Python\Python311\Scripts
次の行がPATH内にあれば削除
C:\Users\{ユーザ名}\AppData\Local\Programs\Python\Launcher
※py と入力すると python を実行するようになるランチャー 環境変数を修正している様子
Pytorchをインストールする
Pythonの機械学習用ライブラリであるpytorchをインストールします。
公式サイト( https://pytorch.org/get-started/locally/ )にアクセスすると、インストール用のコマンドを発行できます。
CUDA Version: 12.9 をダウンロードすればいいのですね
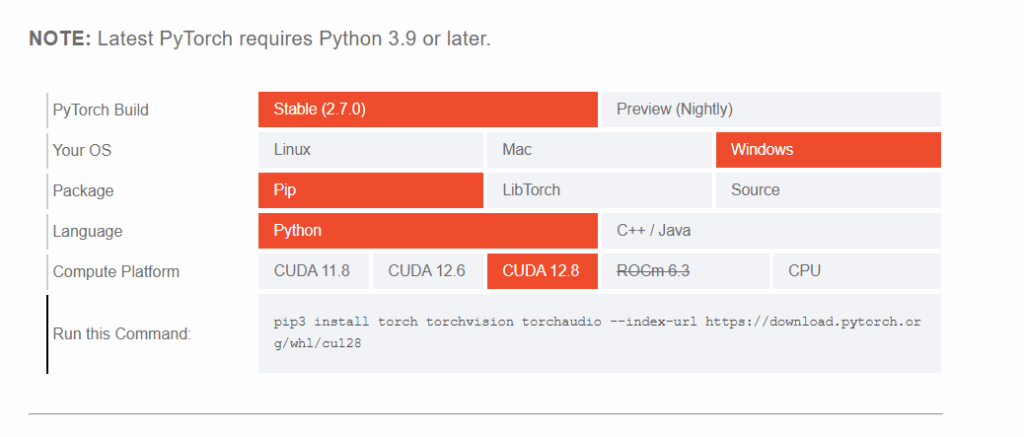
12.9がないので、とリあえず12.8を使いました。
発行されるpipコマンドをコマンドプロンプトから実行すると、pytorchがインストールされます。
コマンドプロンプト
pip install typing-extensions
c:\ > pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu128
# インストールが始まるテキストを画像に変換するモデルの入手
今回は、人気の高いstable diffusionを使いました。
モデルの入手先は、Hugging Face – The AI community building the future.を使用します。
初回の起動時に、無料アカウントを作成しました。
アバターの画像を選んだりします。
ログインが成功した後、右上に「Resend confirmatione mail」と表示されていると思います。
これは、メールアドレスの確認が終わっていないという意味で、登録したメールアドレスにURL入りのメールが届いていますので、このURLリンクを開いてアクティベートします。
(メールの確認が終わらないとトークンを発行できません)
トークンの作成方法
ログイン後、ホーム画面の左のメニューから、「Profile」ー「settings」ー「Access Tokens」を選択
「create new token」を選択するとトークンを発行できます
token name に適当な名前を入れて、RepositoriesとInferenceのチェックを入れました。
トークンIDが発行されるので、テキストファイル等にコピペして、誰にも教えないようにしてください。
トークンの登録方法(ログイン方法)
コマンドプロンプトから次のコマンドを入力し、トークンを入力しておきます。(ログイン)
# コマンドプロンプト
# ログイン用ライブラリのインストール
c:\ > pip install -U huggingface_hub
# ログイン
c:\ > huggingface-cli login
To log in, `huggingface_hub` requires a token generated from https://huggingface.co/settings/tokens .
Token can be pasted using 'Right-Click'.
Enter your token (input will not be visible):***** ←ここでトークンを張り付ける
Add token as git credential? (Y/n) Y
Token is valid (permission: fineGrained).
The token `***** has been saved to C:\Users\{ユーザ名}\.cache\huggingface\stored_tokens
Your token has been saved in your configured git credential helpers (manager).
Your token has been saved to C:\Users\{ユーザ名}\.cache\huggingface\tokenLogin successful.
The current active token is: `*****`モデルのダウンロード
huggingfaceでは、リポジトリのダウンロードにpythonプログラムを使うんですね。
次のコマンドでモデルをダウンロードしました。
stable-diffusion-v1-5のモデルサイズは44GBもあります。ダウンロードに2時間程度かかりました。
# ダウンロード用python download.py としてc:\{インスト―ル先フォルダ}に保存
from huggingface_hub import snapshot_download
# 推奨
model ="runwayml/stable-diffusion-v1-5" # モデル名 変更可能
# 非推奨
# model ="stable-diffusion-v1-5/stable-diffusion-v1-5" # モデル名 変更可能
local_dir = "./stable-diffusion-v1-5" # 保存先 変更可能
snapshot_download(repo_id=model, local_dir=local_dir, token=True)
# コマンドプロンプト
# インストール先へ移動
c:\ > cd c:\{インスト―ル先フォルダ}
# 必要なライブラリをインストール
c:\ > pip install diffusers torch transformers accelerate
# ログインが必要(ログインしていれば飛ばす)
c:\ > huggingface-cli login
Enter your token (input will not be visible):***** ←ここでトークンを張り付ける
# ダウンロードの実行
c:\ > python download.py
# カレントディレクトリに「stable-diffusion-v1-5」というフォルダができていればダウンロード完了実行
実行前の確認
CUDAが正常に稼働しているか次のプログラムで確認します。
# CUDAの動作チェック
c:\ > python -c "import torch;print(torch.cuda.is_available())"
True
# True と表示されていればCUDAが実行可能
# pytorchのバージョンチェック
c:\ > python -c "import torch; print(torch.__version__)"
2.7.1+cu128
# ライブラリのバージョンチェック
# 当環境で動作したライブラリのバージョンを残しておきます
c:\ > pip list
Package Version
------------------ ------------
accelerate 1.7.0 ← 重要
certifi 2025.4.26
charset-normalizer 3.4.2
colorama 0.4.6
diffusers 0.33.1 ← 重要
filelock 3.18.0
fsspec 2025.5.1
huggingface-hub 0.32.4 ← 重要
idna 3.10
importlib_metadata 8.7.0
Jinja2 3.1.4 ← 重要
MarkupSafe 3.0.2
mpmath 1.3.0
networkx 3.5
numpy 2.3.0
packaging 25.0
pillow 11.2.1
pip 25.1.1 ← 重要
psutil 7.0.0
PyYAML 6.0.2
regex 2024.11.6
requests 2.32.3
safetensors 0.5.3
setuptools 80.9.0
sympy 1.14.0
tokenizers 0.21.1
torch 2.7.1+cu128 ← 重要
torchaudio 2.7.1+cu128 ← 重要
torchvision 0.22.1+cu128 ← 重要
tqdm 4.67.1
transformers 4.52.4 ← 重要
typing_extensions 4.14.0
urllib3 2.4.0
wheel 0.45.1
zipp 3.23.0
# バージョンアップでライブラリのバージョンが変わると、途端に動かなくなることがありました画像生成
次のプログラムを実行することで画像を生成できます。
# make.py という名前で"stable-diffusion-v1-5"と同じフォルダに配置
import torch
from diffusers import StableDiffusionPipeline
from datetime import datetime
model = "./stable-diffusion-v1-5"
pipeline = StableDiffusionPipeline.from_pretrained(model)
pipeline = pipeline.to("cuda")
# プロンプト 火星で馬に乗る宇宙飛行士の写真
prompt = "a photo of an astronaut riding a horse on mars"
negative_prompt = "low quality,blurry"
responce = pipeline(prompt = prompt,negative_prompt = negative_prompt )
image = responce.images[0]
filename = datetime.now().strftime("out_%Y%m%d%H%M.png")
image.save(filename)実行すると次のようになります。
# 実行する様子
c:\ > python make.py
Loading pipeline components...: 100%|█████████████| 7/7 [00:00<00:00, 19.56it█████████████| 50/50 [00:13<00:00, 3.70it/s]
出力した画像がこちらです。

いい感じで出力できていると思います。
画像崩壊もなさそうですし、これなら使えそうですね。

さっきの画像が良かっただけに残念です。
背景に映っているのは地球だと思うのですが、馬の成分はどこに行ったのでしょうか。
宇宙空間でタイヤがついている乗り物に乗っている時点で意味不明w
なにはともあれ、画像の生成が無事できました。
Copilot等の画像生成AIはありますが、無料だと生成回数に制限があるので、ローカル環境で生成すれば生成し放題です!(GPU代金、電気代で元を取ることはないと思いますが)
実行速度
当環境で、一枚の画像を出力するににかかった時間は低画質モードで
CUDA使用(GPU) 21秒
CUDA未使用(CPU) 3分36秒
でした。
CUDAってやっぱり早いんですね。
CPUパワーで生成できなくもないですが、GPUの恩恵を感じることができました。
ライセンス
stable-diffusion-v1-5の本日時点のライセンス(2024/7/5版)を確認したところ、ざっくりと
商用利用は可能であり、その責任は自分自身で負うこと
モデルから生成された出力の権利は原則としてユーザーにあるただし、ライセンス違反でないこと
ライセンス違反になる項目
法律違反、未成年者への害、虚偽情報の拡散
個人情報の悪用、誹謗中傷・嫌がらせ、自動化された法的判断や契約の強制
差別的・有害な利用、医療診断や助言、司法・警察・移民関連の判断補助
こんな感じでした。
実際に使う場合は、確認してから使いましょう。
最後に
問題になることも多い生成AIですが、私は使える技術はどんどん使うべきだと思っています。
使ってみた上でルール作りや、問題点の洗い出しをしていけばいいのではないでしょうか。
AIを使うとダメ人間になるなどという人もいますが、むしろ、人間がボトルネック化して、人にしかできない判断をするために休めなくなる未来が怖いです。(携帯電話の普及によって休日でも連絡がつくようになり、休暇が休暇でなくなったように)
AIに頼ってダメ化する人は、AIがなくてもダメ化すると思います。私はAIが出てきてから今までできなかったことができるようになり、やりたいことが増えすぎて忙しくなりました。
今後AI関連技術が衰退することは絶対にないと思いますので、早くAI慣れしたい!